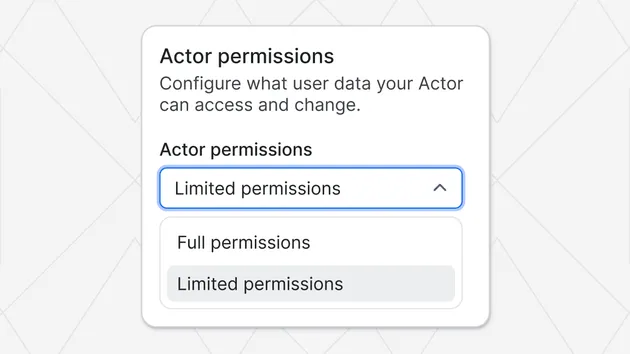
1import scrapy
2import re
3
4
5class ChampionsLeagueSpider(scrapy.Spider):
6 name = 'championsleaguespider'
7 start_urls = ['https://www.uefa.com/uefachampionsleague/season=2018/clubs/']
8
9 custom_settings = {
10 'USER_AGENT': 'DDWcrawler',
11 'ROBOTSTXT_OBEY': True,
12 'DOWNLOAD_DELAY': 0.001,
13 }
14
15
16 def parse_phase(self, fields):
17 phase = {}
18 for field in fields:
19 label = field.css('.statistics--list--label::text').extract_first()
20
21
22 if (label == 'passing accuracy'):
23 value = field.css('.graph-circle--additional-text::text').extract_first()
24
25
26 elif (label == 'Cards'):
27 cards = field.xpath('.//span[@class="statistics--list--data"]/text()').extract()
28 labels = field.css('.statistics--list--data img::attr(title)').extract()
29
30 yellow = re.findall('\d+', cards[0])
31 red = re.findall('\d+', cards[1])
32
33 value = {
34 labels[0].lower().replace(" ", "-"): yellow[0],
35 labels[1].lower().replace(" ", "-"): red[0],
36 }
37
38
39 elif (label == 'Passing types'):
40 types = field.css('.statistics--list--data .graph-bar-container .bar-container')
41 value = {}
42
43 for type in types:
44 pass_type = type.css('span:not(.bar)::text').extract_first()
45 type_label = pass_type.split(' ')[1].lower()
46 type_value = type.css('span:not(.bar) b::text').extract_first() + ' ' + \
47 pass_type.split(' ')[2]
48 value[type_label] = type_value
49
50
51 elif (label == 'Type of goal'):
52 types = field.css('.statistics--list--data .graph-dummy-container > div')
53 value = {}
54 for type in types:
55 type_label = type.xpath('.//span/text()').extract()
56 type_value = type.css('div > span::text').extract_first()
57 value[type_label[1].lower().replace(" ", "-")] = type_value
58
59
60 else:
61 value = field.css('.statistics--list--data::text').extract_first()
62
63 phase[label.lower().replace(" ", "-")] = value
64
65 return phase
66
67
68 def parse_stats(self, response):
69 player = response.meta['player']
70 stats_sections = response.css('.player--statistics--list')
71 player['matches'] = {}
72
73 for section in stats_sections:
74 fields = section.css('.field')
75 phase_name = section.css('.stats-header::text').extract_first()
76
77
78 if (phase_name == 'Tournament phase'):
79 player['matches']['tournament'] = self.parse_phase(fields)
80
81
82 elif (phase_name == 'Qualifying'):
83 player['matches']['qualification'] = self.parse_phase(fields)
84
85 yield player
86
87
88 def parse_player(self, response):
89 stats_url = response.css(
90 '.content-wrap .section--footer a[title="More statistics"]::attr(href)').extract_first()
91
92 for player in response.xpath('//div[@class="content-wrap"]'):
93 bio = {
94 'name': player.css('.player-header_name::text').extract_first(),
95 'position': player.css('.player-header_category::text').extract_first(),
96 'team': player.css('.player-header_team-name::text').extract_first(),
97 'nationality': player.css('.player-header_country::text').extract_first(),
98 'birthdate': player.css('.profile--list--data[itemprop=birthdate]::text').extract_first().split(' ')[0],
99 'height': player.css('.profile--list--data[itemprop=height]::text').extract_first(),
100 'weight': player.css('.profile--list--data[itemprop=weight]::text').extract_first(),
101 }
102
103 if (stats_url):
104 yield scrapy.Request(response.urljoin(stats_url), callback=self.parse_stats, meta={'player': bio})
105 else:
106 yield bio
107
108
109 def parse_clubs(self, response):
110 players = response.css('#team-data .squad--team-player')
111 players_urls = players.css('.squad--player-name > a::attr(href)').extract()
112
113 for player_url in players_urls:
114 yield scrapy.Request(response.urljoin(player_url), callback=self.parse_player)
115
116
117 def parse(self, response):
118 clubs = response.css('.teams-overview_group .team > a')
119
120 clubs_tocrawl = clubs.css('::attr(href)').extract()
121
122 for club_url in clubs_tocrawl:
123 yield scrapy.Request(response.urljoin(club_url), callback=self.parse_clubs)